Individual Developments and Systemic Change in Philology
Gregory Crane
May 1, 2018
At the end of March 2018, my collaborators and I finished enjoying five years of support—5,000,000 EUR(!)—from an Alexander von Humboldt Professorship, support which allowed young researchers from many different countries to work both as a team and on their own. Documenting all that work will be a significant task and requires its own publication(s). Work, at Leipzig, Tufts and elsewhere, on Open Greek and Latin (OGL [1] ) and on the Canonical Text Services (CTS) protocol upon which OGL builds provides the starting point for much of the work described below. A tremendous amount of support for OGL came from the European Social Fund and the Alexander von Humboldt Foundation, but collaborators at Perseus at Tufts University, at Mount Allison University in Canada, at the University of Virginia, at the Harvard Library and Harvard’s Center for Hellenic Studies (CHS) have contributed time and significant sums as well. As a group, they have made 37 million words of Greek and Latin available in CTS-compliant epiDoc TEI XML via GitHub.
This paper, however, does not focus primarily upon what happened at Leipzig but takes note of a number of events that have taken place in the opening months of 2018 and that have some connection to, but also depend upon efforts outside of, the Digital Humanities Chair at Leipzig. Each taken separately is important. All of these events taken together reflect a broader, systemic change—and change for the better—in Ancient Greek and Latin philology in particular and, ultimately, for all philology.
All scholarship reflects the particular point of view that one or more authors articulate at a particular time and in a particular context. This paper refers to rapidly changing work, and the field will continue to evolve. Discussing in written form the state of this evolution at particular points in time is important not only to spur further thought in the present but also to document events for the future. In the 1980s, I wrote a short monograph about the work that had been done to make the Thesaurus Linguae Graecae available on a Unix server. I set it aside because a colleague who had reviewed the monograph (and who was himself a pioneer in Digital Classics) commented that the technological approaches that I articulated would soon be—as they indeed now are—outmoded. I set the monograph aside and it has vanished into the digital ether. I now regret that because that monograph would have shed very precise light on a moment in the study of Greek and Latin that may have passed but that represented a distinct stage in the history of that field.
I personally use the term philology in a specifically expansive sense that I often illustrate with a textual variant. As a first year student in Cedric Whitman’s Greek survey course, I recall hearing him quote August Boeckh as describing philology as the scientia totius antiquitatis. Philology exploited every possible method to extract from every surviving textual source as much understanding about the past as was humanly possible. A generation later, when I went in search of this quote, I found that Boeckh had, in a 1822 birthday oration for the King of Prussia, described philology as the cognitio universae antiquitatis.
While I find little significance in the variation between totus and universus, I would use the variation between scientia and cognitio to sharpen the expansive definition of philology. I would apply scientia to specialized academic research produced to satisfy a bureaucratic requirement. A student submits a PhD dissertation. A specialist committee reads it and certifies that this document taught them something new that they otherwise did not know and could not otherwise have looked up in the published literature. Before digital publication, dissertation often vanished into the archives and, even now in an age of digitization, may never be seen again if the PhD is not immediately made available and the author moves on to some new project or career. The committee members forget whatever it was that they had learned from the dissertation. This pattern is not universal but it has repeated itself in many countries over many years.
Boeckh’s Latin term cognitio means something very different to me. Cognitio implies a human brain at work—it implies that something published has attracted attention and changed the way a living being thinks about and understands the past. An article or book unread on the shelf cannot produce cognitio until one or more human beings engage with it and the neurons in their brains begin to fire in response. Philology is a lived process and has meaning only insofar as it fires human minds with curiosity and passion (however much reserve we may use to conceal that passion). In my view, specialist networks only have value insofar as, and to the degree to which, they advance the intellectual life of society as a whole. Those of us who are lucky enough to receive paychecks to be scholars are employees, entrusted with the duty to open up our field and to help others integrate Greek and Latin in their thinking. Those of us who are specialists can play an essential role but we are a means to an end and constitute the least important audience.
The common thread among all these developments reflects changes in the practices and, most importantly, the participants in the study of Ancient Greek and Latin. They are important because they illustrate how people who are not paid to study Greek and Latin contribute to, and indeed can establish resonant voices within, the study of the past. For those of us who draw a paycheck for advancing Greek and Latin, the job is to help this wider circle of contributors as much as we humanly can. If we feel that there are ways in which others might more effectively contribute, then we must do everything that we can to help.
From Scans to Machine Actionable Text
The Internet Archive, the HathiTrust, Google Books and the varied European libraries visible from Europeana [2] have photographed every page in millions of printed books. But while many of these books are available to a global audience as downloadable PDFs, the optical character recognition (OCR) software which extracts machine readable text from images of print has produced uneven, if not unusable, results for books that do not resemble modern publications in economically important modern languages. [3] The systems that have helped scholars search JSTOR, for example, do not help with Ancient Greek (whether the printed book is recent or centuries old) and provide very poor results for German Fraktur and even for early modern English. While it is an immense help to be able to carry a library of early modern books on a tablet or notebook computer, we need machine readable text for serious modern scholarship.
If we could generate machine readable text for historical books available as images, we would rewrite the intellectual history represented by these books from the ground up. We cannot overstate the potential impact. The technology does not need to be developed—it already exists, and, indeed, the services and data are already available, but unused. Consider, for example, a system developed by researchers at the University of Massachusetts and Northeastern University:
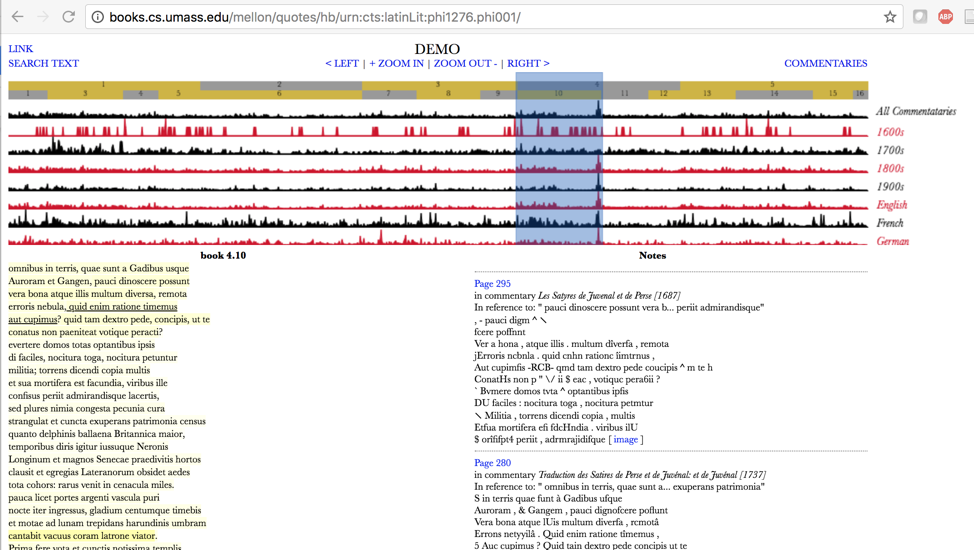
The screenshot above shows the results from scanning the uncorrected OCR-generated text of 3 million books for quotations of Juvenal through the 19th century, in English, French and German books. The system provides useful results despite the high error rate in OCR that was not optimized for Latin. This browsing environment exists and has existed for several years. The time will come—perhaps five, ten or twenty years from now—when every student of reception will start—and start they should—with a version of the system above. Almost all students of reception will assume that they would have seen the importance of this system immediately. The first researchers who seize upon this tool and exploit it have a chance to lead a reinvention of reception studies.
The quotation detection service above is only one of a growing set of tools, including topic modeling, sentiment detection, named entity recognition and linking, and various forms of linguistic analysis. [4] Instead of being limited to the books that we can ourselves read (and to which we happen to have access), we will be able to develop a new, hybrid scholarship that integrates traditional close reading with a growing range of automated methods of text mining and visualization. The research questions that we pose, the skills that we acquire, the audiences that we can reach, and the fundamental relationship between the study of the print record and society as a whole are liable to change in ways that we may not be able to predict but that are unlikely to be mundane. We will still be engaging with the past and, in a sense, the larger purpose of scholarship may remain the same, but we should prepare for a shift at least as dramatic as that which happened when modern, professionalized academic disciplines emerged in the 19th century.
Two events on both sides of the Atlantic point the way forwards. On February 7-8, 2018 with support from the Mellon Foundation, researchers gathered at Northeastern to develop “an agenda for historical and multilingual OCR.” [5] Participants included academics working on Classical Chinese, Classical Arabic and Persian, 18th century English publications, computer science, the National Endowment for the Humanities (NEH) as well as the Mellon Foundation, and Google. Increases in computing power, rapid development of a new generation of OCR systems based upon neural nets and deep learning, more training data, and more scholarly engagement have greatly expanded our ability to extract text from images of historical books and enhanced our ability to analyze complex sources in a range of historical languages.
A month later, on the other side of the Atlantic, eight coordinated projects, funded by the German Research Foundation (the DFG), gathered to begin an 18-month development sprint aimed at creating an OCR workflow for the documents being digitised in the context of the “VD-Projects” (Verzeichnisses der im deutschen Sprachraum erschienenen Drucke), the VD16, VD17 and VD18. [6] The funding, the projects and the partners are German. The language of the conference was German and the materials upon which this project focuses (at least initially) are those in German collections. The projects will inevitably pay particular attention to the challenges of German print (and the difficulties of Fraktur print make this focus particularly welcome). The name of the project itself—OCR-D—points to its identity as a German effort. But the technology is completely general and would work for any collection of scanned books. The OCR-D workflow would work for books in the Internet Archive and HathiTrust as well. The implications for the Humanities are vast. The researchers who gathered at Northeastern and the coordinated projects of OCR-D are building a Hubble telescope for the printed record.
The German Digital Library collects books in German published anywhere but it also collects books in any language that were published in the German speaking world. Thus, if German is the primary focus, Ancient Greek and Latin also play significant roles in the German Digital Library. The German DL reports, on April 16, 2018, that it contains 8,374 scanned texts in Ancient Greek—even at 15,000 words per text, this would contain more than 100 million words of Greek. But, of course, the impact of generating machine readable Latin from this one national digital library is unfathomable: the German DL reports that it contains 473,263 Latin texts. In the first three centuries of print, the number of Latin and German texts are almost the same (228,280 Latin vs. 237,694 German). As collections from other European nations become increasingly available in digital form, the number of Latin printed texts will surely reach into the millions. For the first time, we will be able to analyze the vast—and almost forgotten—Latin space within which European culture and the idea of Europe largely took shape. This collection includes not only editions of Classical and Christian authors but early modern Latin literature and technical publications on every subject on which European intellectuals expressed themselves in writing.
We are poised for a golden age of Latin studies, one that embraces the full scope and range of intellectual life conducted over thousands of years in this Latin. But we should also note that this revolutionary development did not emanate from departments of Classics, in Germany, in the United States and elsewhere. Librarians and computer scientists have taken the lead and the great transnational heritage of Latin is being developed insofar as it contributes to the national cultural heritage of modern European languages. Here we see a common theme in the fundamental changes taking place in philology: with a handful of notable exceptions, the professional academics paid to study and advance Greek and Latin are not a driving force and often (as here) do not appreciate the importance of changes that others have already implemented.
The Scaife Viewer and the CHS Commentary System
The second development is deceptively simple: the appearance of a new online commentary. Online commentaries are, of course, nothing new—the work for Perseus began when I was able to get a handful of Xerox Machines in 1985 so that I could work with the Notecards Hypertext system (https://en.wikipedia.org/wiki/NoteCards) that Randy Trigg, Frank Halasz, and Tom Moran began in 1984. The core problems have been scalability and sustainability. How do we create a commentary environment that can work with any relevant text (for us in this context, any surviving Greek or Latin source)? How can we create born-digital commentaries that have the best possible chance of being useful generations and centuries from now? Of course, people may choose to work with other commentaries but they should make that choice based on the quality of the content—not because later systems can no longer support older material.
As noted above, 50 million words of Greek and Latin are available on GitHub. Thibault Clérice, then at Leipzig, and Bridget Almas, then at the Perseids Project at Tufts, developed a scalable CTS production workflow and backend server. [7] On March 15, 2018, the web development company Eldarion, [8] working with support from the Alexander von Humboldt Chair of Digital Humanities at Leipzig, produced the Scaife Viewer, [9] the first version of a reading environment for OGL and for any corpus that used the Capitains CTS-services. On April 4, 2018, the web development firm, Archimedes Digital, [10] working with Harvard’s CHS (and building on the lightweight CTS server that Thomas Koentges of Leipzig had developed), [11] made available an Application Programming Interface (API) [12] that takes a machine-readable citation [13] as an input and returns available commentary for the passage designated by the URN. This provides access to ongoing commentaries under development at the CHS on key authors such as Homer and Pindar.
As of April 11, 2018, the two efforts were linked: readers using the Scaife Viewer now automatically see commentary from the CHS. A great deal needs to be done—you need, for example, to have the precise URN, internal links within the commentary need to be added, and the commentary is easy to miss, given the initial screen design—but the basic functionality is there. The CHS has already made commentary available in more traditional digital media (if that statement is not too oxymoronic). [14] For example, one may now read comments by Greg Nagy [in the lower right corner] on the meaning of the Greek word mênis while reading the Iliad in the Scaife DL Viewer. [15]
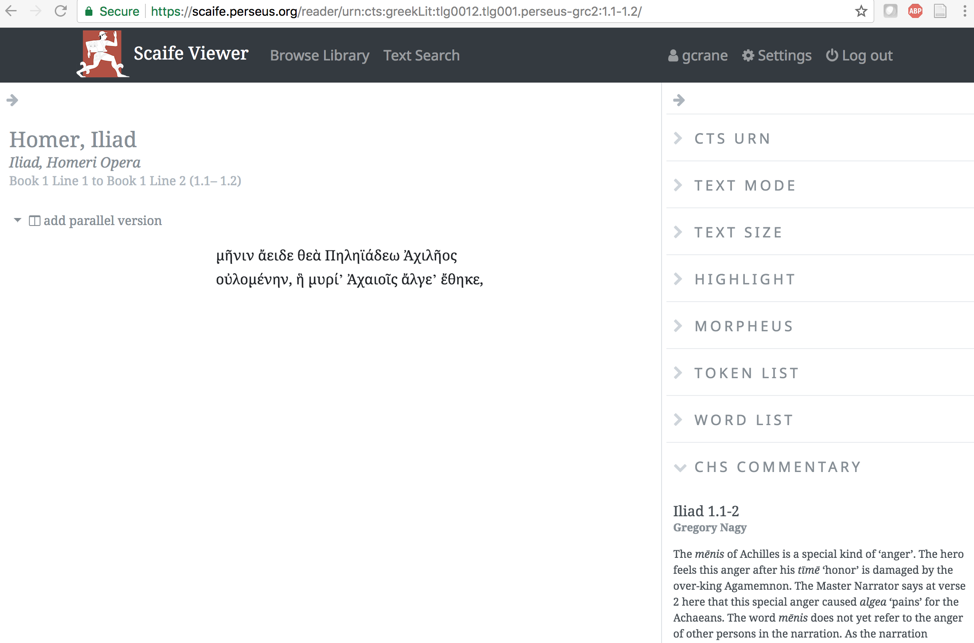
The principle represents a fundamental step forward and creates the possibility for an ecology where open commentaries rapidly emerge. A range of challenges remain but those barriers will all ultimately fall. The question is whether now is the time. There is an excellent chance that it is.
First, there is the question of scale and coverage. The new commentary environment linking Perseus and CHS can support commentaries on any CTS-compliant text in Ancient Greek, Latin, or any other language. While commentaries take a long time to develop and the CHS is focusing on a smaller number of key texts, the architecture in place would recognize any commentary on any text that shares the same CTS identifier. The same server could provide commentary from any source: digitized print commentaries (e.g., the commentaries by Benner and Seymour that Perseus digitized), born-digital commentaries (like the one being developed by Greg Nagy, Lenny Muellner and their collaborators), or even ancient scholia. We do not have commentary on Thucydides or Plutarch—but, if we did, it would be visible to anyone reading relevant passages in the Scaife Viewer. The current system already identifiers the source for particular commentary entries and thus allows readers to select (or avoid) particular commentaries. The potential visibility of such commentaries is immense, especially as a growing share of the 3.4 million Perseus yearly users shift from the current Perseus Digital Library website (http://www.perseus.tufts.edu/—Perseus 4.0) to the Scaife Viewer (Perseus 5.0). As visibility increases, the potential impact and intellectual satisfaction from creating commentaries also increases. The combination of the Scaife Viewer and CHS Commentary system provides an infrastructure to support commentaries on any Greek or Latin text—indeed on any text in any language—that has a CTS URN.
Second, beyond the technology, the Perseus Digital Library and the CHS Commentary are both digital resources with long-term institutional backing. Tufts University has provided concrete support for the Perseus Digital Library since 1997 and continues to demonstrate a commitment to maintaining it over time. Its MA Program in Digital Tools for Premodern Studies has just completed its first year and its students will, it is hoped, increasingly contribute to the network of resources that Perseus (and other openly licensed digital projects) produce. The established Perseus website reflects a design that is now fifteen years old and a chief challenge has been flexibility: it has been very difficult to add new features and even to update the site. The Scaife Viewer (and the Capitains CTS backend, http://capitains.org/, upon which it builds) vastly simplify the tasks of adding new textual data and integrating new services (such as the CHS commentary). New contributions by Tufts students, at both the BA and MA level, can be seen at https://github.com/ChiaraPalladino/TuftsDCC/wiki. As we add lightweight viewers for morpho-syntactic and alignment data, those contributions will appear in the Scaife Viewer version of Perseus.
The possibilities for the CHS are particularly intriguing. The CHS is an independent research center that provides funding for researchers to conduct their own work. The CHS already aggressively promotes open scholarship and has emerged as a leading force in reforming scholarly publication. It is in the position to spark an intellectually dynamic new generation of born-digital, “smart commentaries” that can adapt themselves to the backgrounds and immediate needs of far more readers than the static publications of print culture. The popular press of 2018 has focused upon the dystopian effects of machine learning applied to user data but those dystopian effects, even if exaggerated for effect, are substantial and provide evidence of a power that can be beneficial as well.
Third, both the Perseus Scaife DL Viewer and the CHS Commentary system are based on open source code, open APIs, and open data. This means that third parties can replicate and/or augment both the services and the data available from Perseus and CHS. New digital editions and new commentaries serving new purposes and giving voice to new points of view can, and hopefully will, emerge. If Perseus and CHS choose not to include them, neither Perseus nor CHS can block others from viewing them—or weaving Perseus and CHS data in with sources with very different points of view. It is simply impossible in a world of openly licensed data for one community to control the information and the points of view that are available to the public.
The goal is not simply to encourage specialists to produce open commentaries for promotion and tenure. If we have a real audience for Ancient Greek and Latin, we will see the emergence of commentaries that answer the questions that confront non-specialist readers and that truly seek to make Greek and Latin sources available to the broadest possible audience. If we do not see such commentaries emerge, then the study of Greek and Latin must rebuild its relationship to society or drift further into scholasticism and ultimately go extinct.
The Scaife Viewer and the CHS Commentary system, however, bear upon the question of whether Greek and Latin still retain an audience beyond paid professionals. Eldarion and Archimedes Digital are both professional development companies and each received money to perform highly skilled work—but, of course, so do university professors of Greek and Latin. But if Eldarion and Archimedes Digital received money for their work, it might be fairer to say that the funding simply made it possible for both companies to support Greek and Latin (as does my own salary as a Professor of Classics). James Tauber and Luke Hollis, the heads of Eldarion and Archimedes Digital, both have training in, and demonstrated commitments, to Greco-Roman culture. James Tauber has done work on Linguistics and Greek for twenty years (http://jktauber.com/), has earned a recent MA in Greek and is considering a PhD on smart systems for learning Greek. Luke Hollis is a poet and translator of Theocritus and Horace. My concern in working with both of these professionals is that I not inadvertently take advantage of the patent love which they have for Greek and Latin. James and Luke are making tangible contributions to the study of Greek and Latin, both in their own capacities and in helping us work with the specialized expertises of their colleagues. These contributions have no real precedent—as late as the 1960s, there was no Digital Classics and there were relatively few ways in which software developers could directly contribute to the field. Even when I began work in what we now call Digital Classics in the 1980s, the theoretical idea emerged but remained implausible that a university would pay for specialists in this field (or in Computing in the Humanities, as Digital Humanities was then called).
There are, of course, dangers inherent in openness and in an open society—it is easy to imagine cultural nationalists, for example, selectively appropriating data in order to paint a picture of Greco-Roman culture that is, depending upon the cultural nationalism involved, either unfairly positive or negative. Foreign governments will, sadly, use any mechanism to diminish their adversaries and the enemies of democracy will exploit the vulnerabilities of an open society. But the only defense against such behavior is, and can only be, as it has always been, the critical abilities and good faith of society as a whole—Thucydides had his Pericles say as much in the Funeral Oration more than two millennia ago. In other words, the only defense for philology must be to make our fellow citizens good philologists. Philology may pose challenges but philology alone can provide the answers.
The Diplomatic Scholarly Edition of the Venetus A manuscript of Homer
On Friday, April 13, 2018, the Homer Multitext Project (HMT) celebrated the (near) [16] completion of a diplomatic scholarly edition of the Venetus A.
“The manuscript Marcianus Graecus Z. 454 [= 822], known to Homeric scholars as the Venetus A, is the oldest complete text of the Iliad in existence. It was acquired by the Greek Cardinal Basileus Bessarion in the 15th century CE and donated together with his entire collection of Greek manuscripts to the Republic of Venice, thereby forming the Marciana library’s initial collection. It is vellum, and was constructed at the end of the 10th century CE. Its size is 39.5cm by 28.5/29cm, with 327 leaves. Several items have been added to the manuscript by later hands, including some short glosses in the exterior margins and between the lines of the poem. A typical folio in the Venetus A contain 25 lines of Homeric text, surrounded on all sides by up to five distinct sets of scholia (marginal, intermarginal, interior, exterior, and interlinear). Main scholia are coordinated with the text via lemmata (short quotations of the relevant text), while the other scholia are linked primarily by relative placement. Other texts of the Venetus A include: excerpts from Proclus’ Chrestomathy (the Life of Homer and summaries of all of the poems of the now lost Epic Cycle except the Cypria) and Aristonicus’ work On the signs of Aristarchus. Painted around this text and in one case over it are illuminations from the twelfth century CE. These illuminations depict mythological scenes from the Judgment of Paris up to the fighting of the Trojan War. The text also notably includes critical signs, which are associated with the edition and commentary of Aristarchus.” [17]
For the sum of $4,138, you can (as of April 15, 2018), purchase the six volume Erbse edition of the Homeric Scholia from Amazon. The Venetus A does not offer an overview of the Homeric scholia as a whole but it is a first step towards a new—and fundamentally superior—aggregate edition of the scholia. The CTS-compliant TEI XML Diplomatic Scholarly Edition of the Venetus A constitutes a fundamental advance over the coverage of the Venetus A in this monumental print resource.
First, it offers a complete transcription of the scholia. Erbse omitted a number of scholia (mainly those focused upon mythological topics), without specifically identifying where or how much he had chosen to leave out.
Second, the Diplomatic Scholarly Edition is based on new, openly-licensed, high-resolution images of the Venetus A themselves. In 2007, the CHS funded a six-week imaging campaign that involved shipping state-of-the-art cameras, computers, and lighting from the University of Kentucky, installing them in the Marciana Library in Venice, and then getting them back to the US in one piece and without running afoul of customs. A relay of classicists and computer scientists supervised the work. The images were available online roughly a week after the hard disks arrived in the US. The visual data upon which the Diplomatic Scholarly Edition is based is visible to the scholarly community as a whole and can be compared to the transcription derived from it. Links can point not only to entire pages, [18] but can include snippets from specific sections of a page. The International Image Interchange Framework (IIIF) (http://iiif.io/) supports links that can in turn connect viewers on-the-fly to specific subsets of an image. The Diplomatic Scholarly Edition of the Venetus A is transparent to a degree that simply has not been possible. Even if the photographic detail of Domenico Comparetti’s 1901 facsimile edition of the Venetus A [19] were as good as the new imaging, only a small number of libraries have the printed facsimile. [20] In print culture, readers needed to have a copy of the Erbse edition and access to the printed Comparetti. Now, anyone with access to the internet can examine Diplomatic Scholarly Edition and source images.
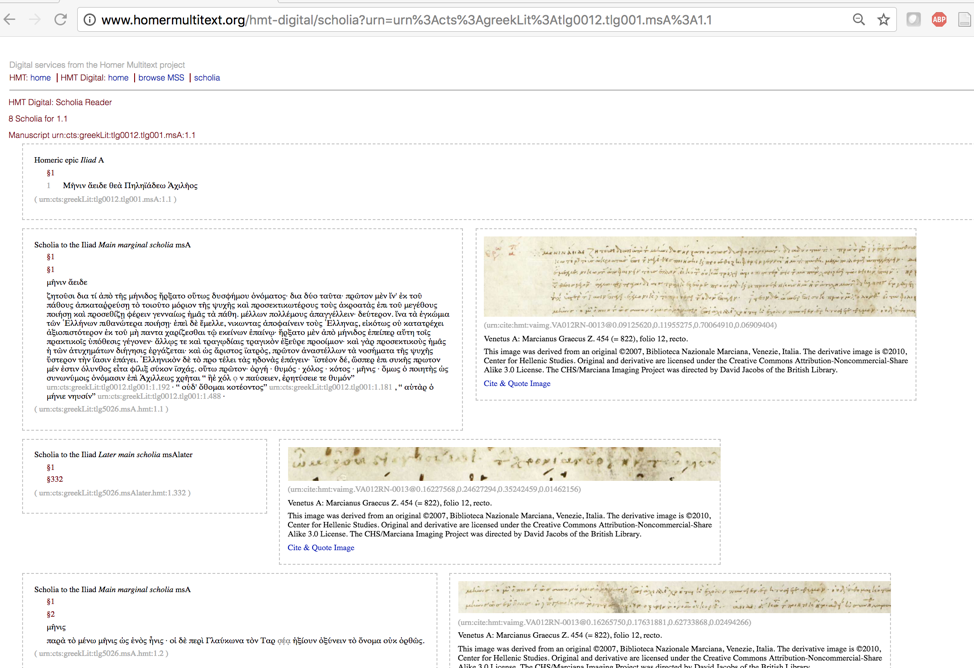
Figure 3: http://www.homermultitext.org/hmt-digital/scholia?urn=urn%3Acts%3AgreekLit%3Atlg0012.tlg001.msA%3A1.1 (one visualization of transcription and source image from the Venetus A)
Third, the Diplomatic Scholarly Edition has been published on GitHub (https://github.com/homermultitext/hmt-archive). GitHub is a site that supports collaborative development of even more complex projects than the Diplomatic Scholarly Edition of the Venetus A. Members of the community can contribute in at least two ways. On the one hand, the data is all openly licensed. If the HMT team were to become unresponsive (and all of us are ultimately unresponsive since none of us are here forever) or if a third party felt that they could do a better job, they are free to use the published work as the basis to create their own version of the Venetus A. Of course, this is what scholars have always done—each edition builds on the editions that precede it—but students of the Greco-Roman world can now take full charge of producing a new edition and they can start with a working digital edition. On the other hand, third parties can submit their own changes and contributions to the HMT Editorial team for inclusion in the ongoing HMT edition. The scholarly world does not need to wait for a new monumental revision. Changes can be added on an ongoing basis. Errata are not slips of paper tenuously attached to a printed book. If there is a community dedicated to studying the Venetus A, then residual errors will be corrected and new features added. This is a dynamic publication, one that will evolve to be as good as its community deserves. The payrologists at Papyri.info have led the way and have used GitHub to provide a dynamic publication environment in place for years but the publication of the Venetus A (and of Greek and Latin texts produced by Perseus and OGL as well as of the Latin texts by CroaLa [21] ) on GitHub illustrates the fact that this approach is not confined to one project.
Fourth (and in my view most important), the Diplomatic Scholarly Edition of the Venetus A represents a new form of intellectual production and, like the linked Scaife Viewer and CHS Commentary, reflects a fundamental change in who can contribute to ancient languages. While faculty at Furman University, the College of the Holy Cross, and the University of Houston led the development of the Diplomatic Scholarly Edition, undergraduates in these institutions and others, both in Europe and North America, were responsible for the editorial work—roughly 200 undergraduates working for almost a decade. Some of the work took place as paid summer research scholarships but much, if not most, was done during the academic year by students working for no academic credit and for no financial reward. The Holy Cross Manuscripts, Inscriptions and Documents Club led the way in demonstrating that our students will go far beyond what (at least some of us) would have thought to be possible. Given an opportunity to advance human understanding, the Venetus A annotators learned (and taught each other) palaeography and scholiastic Greek, as well as a range of technical methods. The faculty were there and, of course, played an ongoing role in providing continuity over generations of undergraduate contributors (in the US system, eight years represents two full generations of four-year students), framing the technical infrastructure, and offering a (constantly evolving) editorial model (with questions, contributions and ideas from the undergraduates constantly fueling the insights of the faculty).
When I first heard that the HMT team planned to have undergraduates play a central role in editing the Venetus A, I simply did not think it was possible. I did not think that undergraduates would be interested in ancient commentaries or in learning how to decode the abbreviations and complex script of the manuscript. I had completely underestimated the idealism and desire to advance human understanding—I had not understood what would happen when our students had an opportunity to become citizens, with a voice of their own, in a Republic of Letters. And I have to say that I am constantly delighted at how wrong I was. Watching the rollout of the Venetus A event at Holy Cross on April 13, 2018, showed me that the study of Ancient Greek and of all ancient languages can have not only a long history but a dynamic future as well.
Reinventing Departments of Classics for a Digital Age: Mount Allison and Furman University, Philology and the Future of Work
Three long term hires over the past several years drew little notice from the handful of big PhD-granting institutions that train the next generation of faculty (if there is to be a next generation) but they represent a future—arguably the core future—for efforts to reestablish the study of Greek and Latin as core elements of a university curriculum. In 2015, the Institute for Classical Studies (https://ics.sas.ac.uk/), under the leadership of Greg Woolf, created a position for a Digital Classicist and an international committee appointed Gabby Bodard, a pioneer in the development of Digital Classics, as a Reader. In the 2016-2017 academic year, Mount Allison University in New Brunswick, led by Bruce Robertson, gained approval for a tenure track position that would not only support the traditional study of Greek and Latin but that would also help develop a new digital curriculum in collaboration with Computer Science. Mount Allison (http://mta.ca/classics/) put itself in a position to provide a new configuration of critical skills to its students, allowing them to immerse themselves in Greek and Latin while graduating with the skills—critical as well as technical—to flourish in a workplace that increasingly integrates machine learning, decentralized contributions from users around the world, and the precious judgment and expertise of core staff. Chris Forstall accepted this position, after having developed extensive expertise working with digital methods for quotation and allusion detection and playing a key role in the Tesserae Project (http://tesserae.caset.buffalo.edu/).
A year later, it was Furman University that took the lead. Impressed with the success of undergraduates such as Sami Strickland ‘15 and Elias Eells ‘16 (whose work in Digital Classics with Chris Blackwell had earned each of them Fulbright Scholarships), [22] the Furman administration increased the size of the Classics Department from three to four faculty. The department made two tenure track appointments, one to Chiara Palladino. Chiara Palladino worked with us at the Humboldt Chair of Digital Humanities at Leipzig. She continued her PhD in Classics at Bari but she worked at the Alexander von Humboldt Chair at Leipzig for the concluding period of her PhD. She distinguished herself by her intelligence and energy at Leipzig. She had the opportunity to spend the 2017 spring semester at Tufts, where she was able to help teach a course on Greek Literature in English translation and an advanced Greek class, learning how the American system worked and getting to know US undergraduates (who had not had years of Greek and Latin at a Liceo Classico).
Beyond this teaching, Chiara built on the model of the Holy Cross Manuscripts, Inscriptions and Documents club and founded the Tufts Digital Classics Club (https://github.com/ChiaraPalladino/TuftsDCC/wiki), which has published, so far, eight student projects.

Figure 4: Tufts Digital Classics Club, March 3, 2017, in the Perseus office, Eaton Hall, Tufts University
When Chiara returned to Europe, she continued to support the Tufts Digital Classics Club remotely, meeting with student members on a weekly basis via Google Hangout video-conference. When Chiara arrives at Furman in the fall of 2018, we will have a distributed Digital Classics Club, with participants at Tufts and Furman initially, but a model that can be replicated at more institutions. Students from small departments in multiple locations will be able to work together and, at the very least, to recognize that they are part of a larger community, one that can extend across many countries and languages.
The Holy Cross Manuscripts, Inscriptions and Documents Clubs are not just distributed systems to generate useful scholarly materials (although they are that). They represent a new mode of intellectual production that challenges students to fashion themselves as citizens in a Republic of Letters, rather than as subjects of a pedagogical machine in which they strive to match preset activities.
I will conclude this section by mentioning, with some hesitation, a development in my own teaching. In fall 2018, I will teach “Working with Corpora,” an advanced course on language technologies in Computer Science (CS 150) and Classics (Classics 191). I quote the course description:
| CLS 0191 01 Working with Corpora Greg Crane 10+ M 6:00-9:00 Cross listed with COMP 0150 |
|
Prerequisites: CS 10, CS 11 or permission of the instructor. [Students need to be able to have an adequate command of Python and to have a sufficiently generalized understanding so that they can work in some fashion with sources in other scripting languages such as R, Go, Java, JavaScript etc.]
This course introduces students to methods for working with corpora and more generalized collections of text. The course builds particularly upon services available in the Natural Language Toolkit, but considers as well other workflows (such as https://weblicht.sfs.uni-tuebingen.de/, https://nlp.stanford.edu/software/, https://gate.ac.uk/, etc.). We will consider how NLP can address the two dimensions of scale: working with more materials than humans can read and working with materials in more languages than human beings can learn. The challenge is not simply to work with large bodies in a handful of languages such as English, Chinese, Spanish and Arabic but in the 24 official languages of the EU, the 22 languages with official standing in India, and historical languages of the human cultural record. “Language wrangling” involves the application of all available methods to push beyond translations, whether produced by machines or humans, and to explore the language directly. Linguists have done this for centuries by adding rich annotation to individual texts. NLP and crowd-sourcing allow us to scale these methods up to large collections. Who this course is for:
|
Teaching this course will be a challenge for me—for years I have spent my time writing grant proposals to enable the next generation of philologists to acquire hands-on facility with a growing range of text analysis and visualization tools. Now I have the chance (and the necessity) to throw myself back into the new literature, rapidly evolving services in a growing range of languages, and vastly expanding collections of textual data of increasingly disparate types. While I remain the immigrant parent who never quite masters the accent or the native culture, I can provide a framework whereby a new generation of students can develop fluency and familiarity with new ways of working with text that can change their lives forever.
I chose the evening time frame so that MA-students with day jobs could participate. Normally, I have at least one in-service Latin teacher in my evening Greek class. Here I hope also to have professional programmers. In this class, the lion may not lie down the lamb, but the Securities and Exchange Commission filing (https://www.sec.gov/edgar/searchedgar/webusers.htm) and the text of Vergil are likely to appear in the same assignments. My goal is to arrange talks by people from Philology and Finance, from International Relations and Reception Studies, from specialists in social media and in the social networks of antiquity. Some of my students may go on to become professional Digital Philologists (or, to be more accurate, Philologists in a Digital Age), but all who master these skills will have the opportunity, if they so choose, to contribute to our understanding of the human record even as they pursue careers outside of academia.
Conclusion
I expect that we may produce very different scholarship as we more fully adapt to the digital age and it is possible that this scholarship will be at once more ambitious and better grounded in evidence. We may experience a golden age of philology. But the most important change is not how philologists feel about each other, it is about how the rest of society feels about philology. It is not how smart we professionals appear but how smart we can make everyone else who is not a professional. Each of the recent advances above can be viewed as important in isolation. Together, they exhibit clear trends in the reorganization of how we study the past and who has a voice.
Footnotes
[ back ] 3. E.g., Christian Reul, Uwe Springmann, Christoph Wick, Frank Puppe, Improving OCR Accuracy on Early Printed Books by utilizing Cross Fold Training and Voting (Submitted on 27 Nov 2017): arXiv:1711.09670 (https://arxiv.org/abs/1711.09670).
[ back ] 4. For work with an earlier billion word corpus of Latin, see http://www.cs.cmu.edu/~dbamman/latin.html.
[ back ] 5. A report is expected in later 2018.
[ back ] 13. A URN compliant with the Canonical Text Services: http://cite-architecture.github.io/cts/.
[ back ] 16. A few small, final contributions are still due but the editors chose to celebrate the completion before the academic year ended.
[ back ] 17. Quotation from http://www.homermultitext.org/manuscripts-papyri/venetusA.html; for a more extensive introduction, see Dué, C. and M. Ebbott. An introduction to the Homer Multitext edition of the Venetus A manuscript of the Iliad. The Homer Multitext, first published 2014.
[ back ] 19. Domenico Comparetti, Homeri Ilias cum Scholiis (1901 facsimile edition of Venetus A); for digitized sample pages of Comparetti, see http://www.homermultitext.org/hmt-digital/browseimg?urn=urn:cite:hmt:compimg.
[ back ] 20. Worldcat lists 81 libraries around the world that claim to have a copy of Comparetti: http://www.worldcat.org/title/homeri-ilias-cum-scholiis/oclc/954197152.
[ back ] 22. Furman students were particularly active at Leipzig: for work by Ellie Daniel, Kimbal Dobbins, ad Sami Strickland, see http://fuluopenphilologyfel.wixsite.com/furman-leipzig; https://github.com/DigitalAthenaeus/homeric-reuse; https://onlinelibrary-wiley-com.ezproxy.library.tufts.edu/doi/full/10.1111/j.2041-5370.2016.12042.x; http://dh2016.adho.org/abstracts/46.